模型篩選
前言
雖然我們知道放入越多變項至模型中,對於模型的解釋力就能更高,但有些變項其實對於解釋力的影響很小,樣本數造成模型不足以放入這麼多變項,
使得變項的結果都不顯著,這時候我們可以藉由模型篩選,留下影響力最大的變項,讓模型去估計變數的效果更好,方法分為:輸入、向前(增加)法,向後
(刪除)法以及逐步回歸分析法,其中輸入只是將所有選取的變項都放入,不做篩選,這裡就不多做說明。
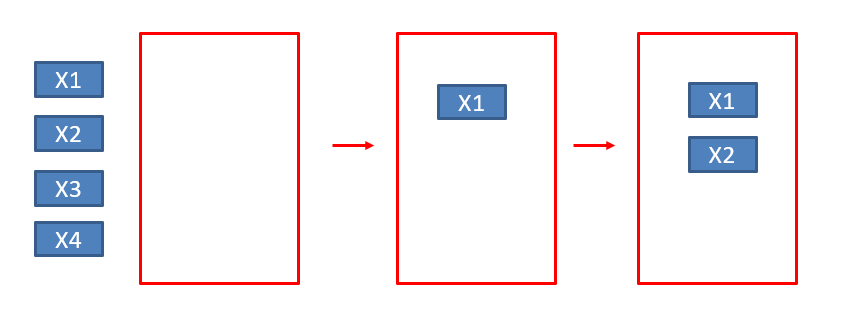
向前(增加)法(Forward selection)
1. 一開始軟體會先評估對於依變數(Y)解釋力(相關性)最強的自變數(X)
2. 把最強的變數放入模型
3. 剩餘的變數再評估解釋力,再將最強的放入模型
4. 重複上述動作,直到系統判定該變數的解釋力不足以放入模型中
向後(刪去)法(Backward selection)
1. 先將所有選取的自變數(X)都放入模型中
2. 軟體會先評估對於依變數(Y)解釋力(相關性)最弱的自變數(X),然後刪除該變項
3. 再評估模型,會再把最弱的剃除
4. 重複上述動作,直到系統判定該模型中剩下的變項的解釋力都足以放入模型中
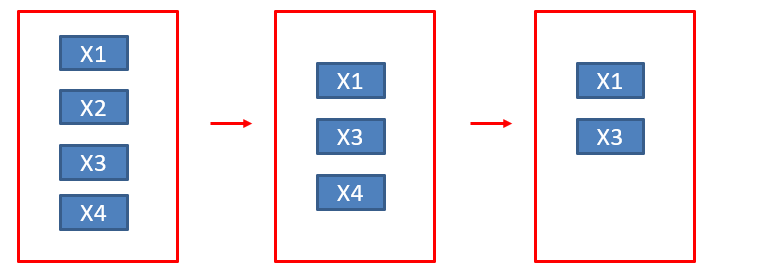
Figure 2. 向後(刪去)法 |
逐步回歸分析法 (Stepwise)
1. 與依變數(Y)相關最強的自變數(X)納入模型
2. 重新評估模型,再將與依變數(Y)相關最強的變數納入
3. 重新評估模型,再將與依變數(Y)相關最弱的變數剔除
4. 重複步驟2與3直到自變數(X)無法被納入與剔除
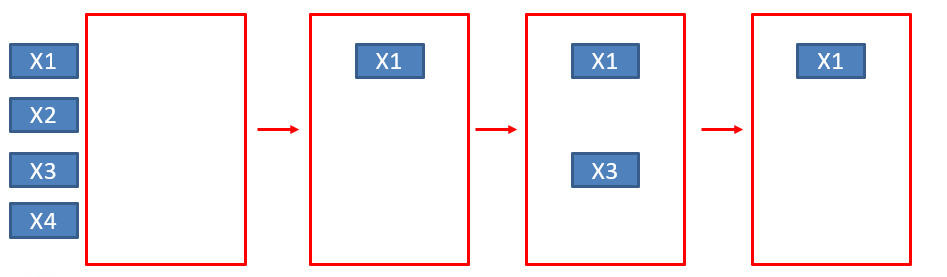
Figure 3. 逐步回歸分析法 |
操作與結果
因為三種的操作與結果解釋皆類似,因此以下將以「向前法」來做範例,並以年齡、性別、舒張壓、空腹血糖、抽菸來估計收縮壓。
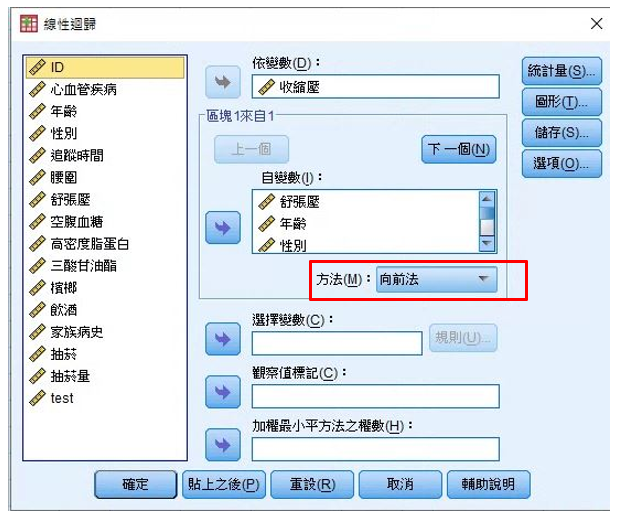
Figure 4為在進行線性回歸時的畫面,紅框處是用來調整模型篩選方法的地方,這裡選擇向前法,其餘操作同於一般的線性回歸。
Figure 5為SPSS計算後的表格,(A)會排列出變項篩選的過程,可以看到舒張壓是在第一個,表示他是相關性最強的,第一個放入模型中。(B)圖中總共產出
了六個模型,可以對照表格下方的註釋a~f對應每一個模型放入了那些變項,接著看到調過後的的R平方,這是考慮到多個變項後,對R2的微調。
模型的篩選沒有標準答案,會依研究者評斷,若以此範例可以看到從模型2到模型3可以增加0.7%解釋力,模型3到模型4的解釋力增加的更少(0.2%),到
了模型5只增加0.1%解釋力,到了模型6就沒有增加了,因此是要停留在模型2還是模型3、甚至模型4,就看研究者的判斷。
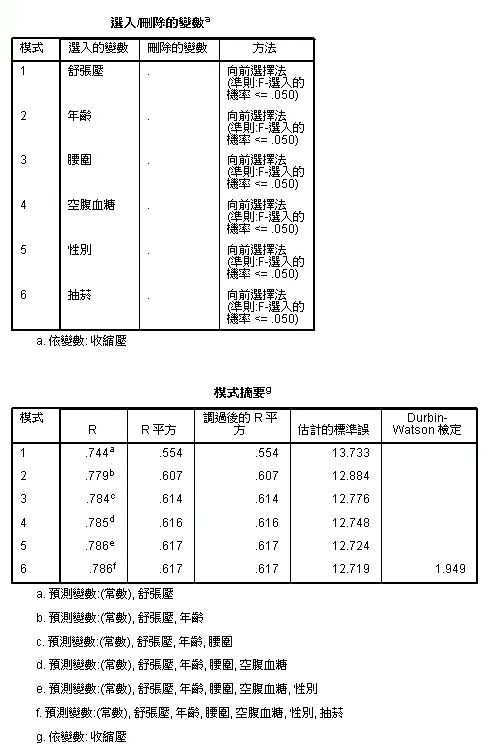
Figure 5 |